Sei un creatore di contenuti o un autore di blog che genera contenuti unici e di alta qualità per vivere? Hai notato che piattaforme di intelligenza artificiale generativa come OpenAI o CCBot utilizzano i tuoi contenuti per addestrare i loro algoritmi senza il tuo consenso? Non preoccuparti! Puoi impedire a questi crawler AI di accedere al tuo sito Web o blog utilizzando il file robots.txt.
Un robots.txt non è altro che un file di testo che istruisce i robot, come i robot dei motori di ricerca, su come eseguire la scansione e l’indicizzazione delle pagine del loro sito web. Puoi bloccare/consentire bot buoni o cattivi che seguono il tuo file robots.txt. La sintassi è la seguente per bloccare un singolo bot utilizzando uno user-agent:
user-agent: {BOT-NAME-HERE}
disallow: /
Ecco come consentire a bot specifici di eseguire la scansione del tuo sito Web utilizzando uno user-agent:
User-agent: {BOT-NAME-HERE}
Allow: /
Dove posizionare il file robots.txt?
Carica il file nella cartella principale del tuo sito web. In questo modo l’URL sarà simile al seguente:
https://example.com/robots.txt https://blog.example.com/robots.txt
Per ulteriori informazioni, consulta le seguenti risorse su robots.txt:
- Introduzione a robots.txt di Google.
- Che cos’è robots.txt? | Come funziona un file robots.txt da Cloudflare.
Come bloccare i bot dei crawler AI utilizzando il file robots.txt
La sintassi è la stessa:
user-agent: {AI-Ccrawlers-Bot-Name-Here}
disallow: /
Blocco di OpenAI utilizzando il file robots.txt
Aggiungi le seguenti quattro righe al tuo robots.txt:
User-agent: GPTBot Disallow: / User-agent: ChatGPT-User Disallow: /
Si prega di notare che OpenAI ha due agenti utente separati per la scansione e la navigazione web, ciascuno con i propri intervalli CIDR e IP. Per configurare le regole del firewall elencate di seguito, è necessaria una profonda conoscenza dei concetti di rete e dell’accesso a livello di root a Linux. Se non si dispone di queste competenze, prendere in considerazione l’arruolamento dei servizi di un amministratore di sistema Linux per impedire l’accesso da intervalli di indirizzi IP in continua evoluzione. Questo può diventare un gioco del gatto e del topo.
#1: L’utente ChatGPT viene utilizzato dai plug-in in ChatGPT
Ecco un elenco degli user agent utilizzati dai crawler e dai fetcher di OpenAI, inclusi CIDR o intervalli di indirizzi IP per bloccare il suo plug-in AI bot che puoi utilizzare con il firewall del tuo server web. È possibile bloccare il comando 23.98.142.176/28 utilizzando il comando ufw o il comando iptables sul server web. Ad esempio, di seguito è riportata una regola del firewall per bloccare il CIDR o l’intervallo IP utilizzando UFW:$ sudo ufw deny proto tcp from 23.98.142.176/28 to any port 80
$ sudo ufw deny proto tcp from 23.98.142.176/28 to any port 443
Blocco di Google AI (API generative di Bard e Vertex AI)
Aggiungi le due righe seguenti al tuo robots.txt:
User-agent: Google-Extended Disallow: /
Per ulteriori informazioni, ecco un elenco degli user agent utilizzati dai crawler e dai fetcher di Google. Tuttavia, Google non fornisce CIDR, intervalli di indirizzi IP o informazioni di sistema autonomo (ASN) per bloccare il suo bot AI che puoi utilizzare con il firewall del tuo server web.
Blocco di commoncrawl (CCBot) utilizzando il file robots.txt
Aggiungi le due righe seguenti al tuo robots.txt:
User-agent: CCBot Disallow: /
Sebbene Common Crawl sia una fondazione senza scopo di lucro, tutti utilizzano i dati per addestrare la propria intelligenza artificiale tramite il suo bot chiamato CCbot. È essenziale bloccare anche loro. Tuttavia, proprio come Google, non fornisce CIDR, intervalli di indirizzi IP o informazioni di sistema autonomo (ASN) per bloccare il suo bot AI che puoi utilizzare con il firewall del tuo server web.
Blocco di Perplexity AI utilizzando il file robots.txt
Un altro servizio che prende tutti i tuoi contenuti e li riscrive utilizzando l’intelligenza artificiale generativa. Puoi bloccarlo come segue:
User-agent: PerplexityBot Disallow: /
Hanno anche pubblicato gli indirizzi IP che è possibile bloccare utilizzando il WAF o il firewall del server Web.
I bot di intelligenza artificiale possono ignorare il mio file robots.txt?
Aziende affermate come Google e OpenAI in genere aderiscono a protocolli robots.txt. Ma alcuni bot AI mal progettati ignoreranno il tuo robots.txt.
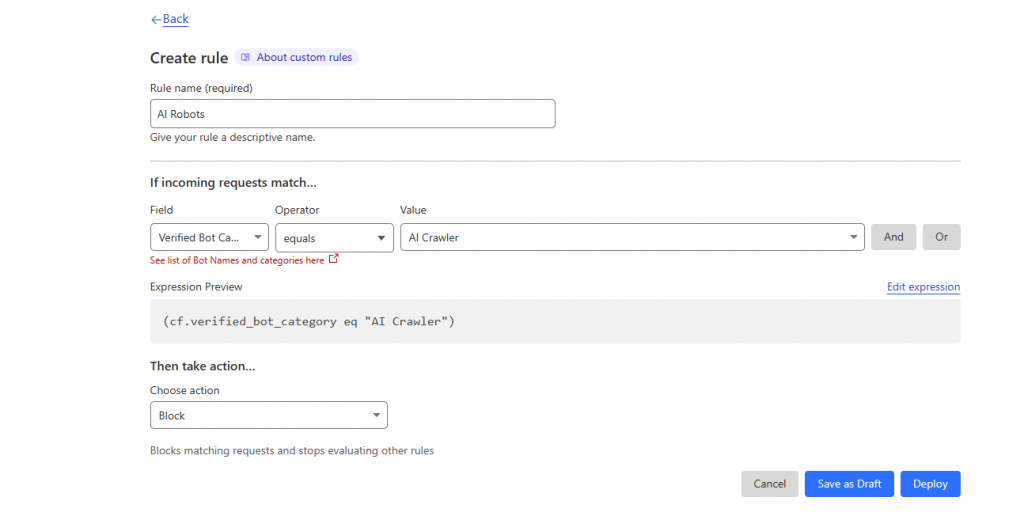
È possibile bloccare i bot AI utilizzando la tecnologia WAF di AWS o Cloudflare?
Cloudflare ha recentemente annunciato di aver introdotto una nuova regola del firewall in grado di bloccare i bot AI. Tuttavia, i motori di ricerca e altri bot possono ancora utilizzare il tuo sito web/blog tramite le sue regole WAF. È fondamentale ricordare che i prodotti WAF richiedono una conoscenza approfondita del funzionamento dei bot e devono essere implementati con attenzione. In caso contrario, potrebbe comportare il blocco anche di altri utenti. Ecco come bloccare i bot AI utilizzando Cloudflare WAF: