

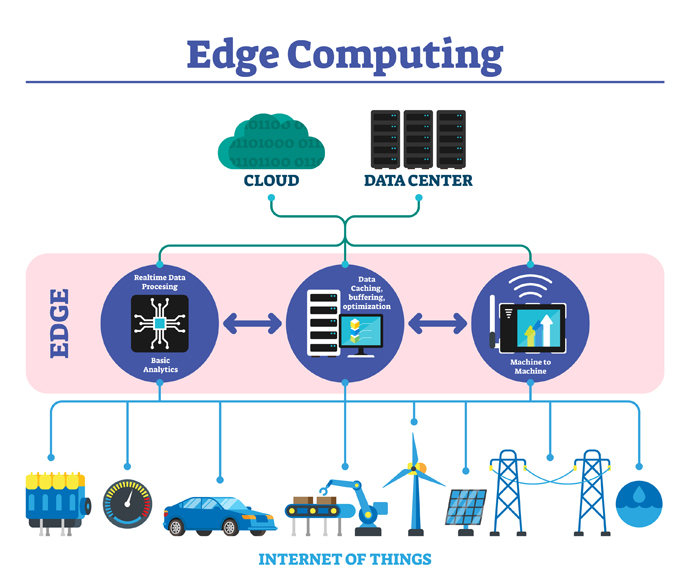
Edge Computing è un’architettura informatica distribuita in cui i dati dei client vengono elaborati nella rete il più vicino possibile alla fonte. Edge Computing; il mobile computing è guidato dal costo ridotto dei componenti del computer e dal numero di dispositivi di rete su Internet of Things (IoT).
A seconda dell’applicazione, i dati sensibili al tempo in un’architettura Edge Computing possono essere elaborati da un dispositivo intelligente o inviati a un server intermedio in una posizione geografica vicino al cliente. Dati meno sensibili al tempo vengono inviati al cloud per analisi storiche, analisi di big data e archiviazione a lungo termine. Edge computing è un metodo per ottimizzare applicazioni o sistemi di cloud computing portando i dati o i servizi di un’applicazione da uno o più nodi a un altro endpoint logico. Cioè, il cloud computing lo trasforma in un’architettura cloud di elaborazione più sofisticata.
Perché è importante Edge Computing
La trasmissione di enormi quantità di dati grezzi su una rete comporta un enorme onere per le risorse di rete. In alcuni casi, è molto più efficiente elaborare i dati vicino alla sua fonte e inviare solo dati di valore sulla rete a un centro dati remoto. Soprattutto per i sistemi Internet of Things (IoT) e i dispositivi integrati, i dati provengono dal mondo fisico con vari sensori e agiscono per cambiare lo stato fisico con varie uscite e attuatori. Ad esempio, invece di pubblicare costantemente dati sul livello dell’olio nel motore di un’auto, un sensore può inviare periodicamente dati di riepilogo a un server remoto. Oppure un termostato intelligente può trasmettere dati se la temperatura supera i limiti specificati. Oppure una videocamera di sicurezza Wi-Fi intelligente posizionata sulla porta dell’ascensore invia i dati quando una determinata percentuale di pixel varia in modo significativo tra le due immagini consecutive. Questo dimostra che c’è movimento.
Edge Computing può sfruttare gli ambienti e le organizzazioni di uffici / filiali remoti con una base di utenti geograficamente dispersa. In tale scenario, è possibile configurare centri di microdati intermedi o server ad alte prestazioni in posizioni remote per replicare i servizi cloud localmente, migliorare le prestazioni e consentire a un dispositivo di lavorare su dati che possono rapidamente fallire.

Sfide di sicurezza: l’architettura distribuita di Edge Computing aumenta il numero di vettori di attacco. Quando sempre più informazioni sui clienti finali sono diventate più vulnerabili, diventano infiltrazioni di malware e vulnerabilità.
Sfide di licenza: sebbene inizialmente la versione base di un cliente Edge abbia un prezzo basso, è possibile concedere in licenza separatamente funzioni aggiuntive e aumentare il prezzo.
Difficoltà di configurazione: a meno che non sia centralizzata e solida, la gestione dei dispositivi può far sì che gli amministratori creino e configurino accidentalmente vulnerabilità della sicurezza non cambiando la password predefinita su ciascun dispositivo Edge o trascurando di aggiornare il firmware in modo coerente.
Quali sono i vantaggi di Edge Computing?
Edge Computing offre molti vantaggi oltre alle architetture tradizionali che aiutano a ottimizzare l’utilizzo delle risorse nel sistema di cloud computing. I processori utilizzati nei dispositivi Edge Computing offrono una migliore sicurezza hardware con requisiti di alimentazione inferiori. Il nome “edge” in Edge Computing deriva dai diagrammi di rete. In genere, il bordo nel diagramma di rete indica il punto in cui il traffico entra o esce dalla rete. Edge è anche il punto in cui il protocollo di base per il trasferimento dei dati può cambiare. Ad esempio, un sensore intelligente può utilizzare un protocollo a bassa latenza, come MQTT, per trasmettere dati a un broker di messaggi situato sul bordo della rete e il broker utilizza il protocollo di trasferimento ipertestuale (HTTP) per trasmettere dati preziosi su Internet lontano dal sensore del server.

Il consorzio OpenFog utilizza le informazioni sulla nebbia per definire Edge Computing. La parola “nebbia” si riferisce all’idea che i vantaggi del cloud computing dovrebbero essere avvicinati all’origine dati. (In meteorologia, la nebbia è solo una nuvola vicino al suolo.) I membri del consorzio includono Cisco, ARM, Microsoft, Dell, Intel e Princeton University.
Edge Computing si riferisce alla potenza di elaborazione dei dati ai margini di una rete, piuttosto che mantenere una transazione in un cloud o in un archivio dati centrale. Diamo alcuni esempi in cui questo è vantaggioso; Nelle applicazioni di Internet of Things come generazione di energia, semafori intelligenti o produzione, i dispositivi periferici acquisiscono i dati di flusso che possono essere utilizzati per prevenire un malfunzionamento di una parte, reindirizzare il traffico, ottimizzare la produzione e prevenire i difetti del prodotto.
L’analisi dei dati è nota come “Edge Analytics” quando eseguita in Edge di una rete. Tuttavia, Edge Computing non sostituisce il cloud computing. In realtà, un modello analitico o regole possono essere creati in un cloud. Inoltre, alcuni dispositivi Edge non possono essere analizzati. Edge Computing è anche strettamente correlato a “Sis IT”, che include anche l’elaborazione dei dati da edge a cloud.
Prima di tutto, dobbiamo dire che Edge Computing ha una speciale infrastruttura informatica disponibile nei bordi delle fonti di dati. I dispositivi (macchine industriali come turbine, sistemi di risonanza magnetica, automobili semoventi, case intelligenti e altri dispositivi intelligenti che prevedono l’inclusione di molti sensori), in altre parole, spingono le applicazioni informatiche dai nodi centrali agli endpoint di rete. Ciò significa che Edge Computing richiede l’uso delle risorse del dispositivo, quindi non deve essere costantemente connesso alla rete (o al centro dati).
Perché abbiamo bisogno della mia Sis Informatics?
La nebbia informatica, ovvero Sis Bilişim, si riferisce all’informatica che si svolge sul dispositivo tra i dispositivi finali IoT e il cloud. Lo spostamento dei dati nel cloud in Fog Computing comporta numerosi passaggi. Questi livelli coprono complessità e trasformazioni di dati.
Per applicazioni critiche come la raccolta e la preelaborazione dei dati, il controllo delle condizioni, il processo decisionale basato su regole e l’archiviazione dei dati a breve termine e che richiedono una risposta in tempo reale, si consiglia il modello di nebbia di calcolo.
Sis Bilişim può essere utilizzato in applicazioni in cui il processo decisionale in tempo reale è fondamentale, come la sicurezza della città, i veicoli autonomi e l’identificazione rapida. Ma il cloud computing è già veloce, quando chiediamo quanto sia critico il tempo trascorso durante il trasferimento da e verso il data center è la massima tolleranza di attesa per il circuito. La velocità della tecnologia cloud sembra sufficiente in queste aree poiché la tolleranza di attesa massima è di oltre 50 millisecondi per applicazioni come navigazione web, video 4K, videoconferenza / VoIP / messaggistica.
Mentre la tolleranza di attesa massima nei veicoli autonomi è di circa 10 millisecondi, si vede che il periodo di tolleranza è inferiore nei punti in cui la vita umana è critica e l’effetto economico è grande. Mentre la tolleranza di attesa degli istituti è di 0,25 secondi nelle transazioni di borsa con transazioni ad alto volume, la tolleranza massima è di 1 millisecondo per garantire la sicurezza dei lavoratori in una miniera. Pertanto, il Fog Computing è necessario per ridurre al minimo il rischio di possibili interruzioni della comunicazione in situazioni critiche come queste, per accelerare l’analisi e il processo decisionale in tempo reale, nonché per ridurre i costi di invio e archiviazione dei dati nel cloud.
In sintesi, Sis Bilişim è un tentativo di avvicinare le forze del computer alle fonti di dati ed eliminare i tempi di risposta senza compromettere l’efficienza. Nel computer Sis, è distribuito nel luogo più logico ed efficiente tra l’origine dati di elaborazione e il cloud. La nebbia è più vicina ai dispositivi a livello regionale rispetto al cloud, ma è ancora una catena media che spinge ancora di più le informazioni se vengono prese alcune decisioni.
Il cloud computing della concorrenza richiede che tutto sia collegato all’archivio dati centrale in cui viene elaborata una grande quantità di informazioni per trovare soluzioni di ottimizzazione o prendere decisioni aziendali. Di norma, il cloud computing è associato a complesse operazioni di elaborazione dei dati che richiedono una notevole potenza di elaborazione. Allo stesso tempo, l’accumulazione e l’elaborazione dei dati non sono abbastanza veloci per essere applicate in alcune aree speciali in cui i risultati del calcolo devono essere applicati istantaneamente.