Non sono così facili da comprendere in una frase, ma per semplicità puoi pensare ai buffer come a un modo per archiviare i metadati dei file (autorizzazioni, posizione, ecc.) durante le operazioni di I/O per un trasferimento efficiente. Mentre la cache viene utilizzata per archiviare il contenuto effettivo del file in memoria per accelerare il recupero futuro.
Cosa sono i buffer e le cache nella memoria Linux?
Forse a un certo punto vi siete imbattuti tutti nei termini “buffer” e “cache” e alcuni di voi potrebbero chiedersi quale sia la differenza tra i due. Se guardi le loro definizioni, noterai che condividono una filosofia simile ma differiscono in termini di funzionalità.
Buffer: un buffer è un’area di archiviazione temporanea nell’elaborazione che contiene informazioni sui metadati dei file come autorizzazioni, posizione, ecc. durante le operazioni di I/O. I buffer sono ampiamente utilizzati in numerosi aspetti dell’informatica, come il networking, le operazioni di I/O e l’elaborazione visiva.
Cache: la memoria cache conserva temporaneamente informazioni e programmi utilizzati di frequente, fornendo un accesso più rapido ai dati per la CPU, poiché la RAM del server è più lenta e si trova più lontano dalla CPU. Un colpo alla cache accelera il recupero dei dati, migliorando l’efficienza del sistema.
Come puoi vedere, entrambi vengono utilizzati per archiviare tipi di dati temporanei ma diversi per accelerare il processo, come le operazioni di I/O o per l’ottimizzazione della CPU.
Ma qual è esattamente la differenza tra loro? Per saperne di più, scaviamo più a fondo.
Differenza tra buffer e cache nella memoria Linux
Per comprendere la differenza tra questi termini, cominciamo a comprendere appieno cosa sono esattamente buffer e cache (2).
Cos’è Buffer?
I buffer sono la rappresentazione del blocco del disco dei dati, che contiene le informazioni sui metadati dei file o i dati durante il trasferimento dei dati da un luogo a un altro archiviati nelle cache delle pagine.
Quando viene effettuata una richiesta di dati nella cache della pagina, il kernel controlla prima i dati nel buffer, che contiene metadati che puntano ai file o ai dati effettivi nelle cache della pagina, fungendo da intermediario.
Solitamente segue sofisticate strategie di gestione, come first in, first out (FIFO) e first come, first serviti (FCFS), per il buffering.
Cos’è Cache?
Una cache memorizza dati o istruzioni utilizzati spesso per accelerare le richieste future mantenendo copie nel kernel, in particolare nella RAM, per migliorare l’accesso ai dati del disco e migliorare le prestazioni I/O, fornendo sostanzialmente un accesso più rapido ai dati rispetto alla fonte originale.
I dati che verranno memorizzati nella cache vengono determinati utilizzando algoritmi complessi e le moderne CPU forniscono un meccanismo integrato per questa attività. Naturalmente non è necessario abilitarli separatamente; sono preconfigurati per il tuo sistema.
Di solito segue strategie di gestione sofisticate, come quelle meno usate di recente (LRU) o quelle meno frequentemente usate (LFU), per decidere quali dati conservare nella cache e quali dati eliminare quando la cache è piena.
Confronto tra buffer e cache
Ecco un confronto affiancato tra cache e buffer in formato tabellare per darti maggiori informazioni:
| Caratteristica | Respingente | Cache |
|---|---|---|
| Scopo | Conserva temporaneamente i dati durante il trasferimento tra due processi o componenti per facilitare un trasferimento efficiente dei dati. | Memorizza dati o istruzioni a cui si accede frequentemente per migliorare la velocità di recupero dei dati. |
| Contenuto | Conserva i dati esattamente come vengono ricevuti. | Memorizza dati o istruzioni a cui si accede frequentemente. |
| Gestione | Solitamente segue una strategia FIFO o FCFS. | Utilizza algoritmi complessi (ad esempio, LRU, LFU) per decidere cosa memorizzare nella cache. |
| Velocità di accesso | Non fornisce necessariamente un accesso più veloce rispetto alla fonte. | Fornisce un accesso più rapido ai dati rispetto alla fonte originale. |
| Esempi di utilizzo | I dati trasferiti tra un disco rigido e la memoria potrebbero essere memorizzati nel buffer. | I browser Web memorizzano nella cache le pagine Web per un caricamento rapido. |
| Posizione di archiviazione | Archiviazione temporanea nella RAM o in altre posizioni di memoria | Tipicamente nella memoria ad alta velocità (RAM o SSD) |
| Controllo di accesso | Gestito dal sistema e talvolta dalle applicazioni | Gestito dal sistema o dalle applicazioni |
| Dimensioni | Le dimensioni del buffer variano a seconda del caso d’uso, ma possono anche essere inferiori alla memoria principale o allo storage. | Le dimensioni della cache sono relativamente piccole rispetto alla memoria principale o allo spazio di archiviazione. |
| Riduzione della latenza | Aiuta a mitigare la latenza ottimizzando il trasferimento dei dati. | Riduce la latenza archiviando i dati a cui si accede di frequente più vicino alla CPU. |
| Utilizzo comune in Linux | Utilizzato nelle operazioni di I/O come la lettura e la scrittura da e verso dispositivi di archiviazione. | Le cache del file system e le cache delle pagine ne sono esempi. |
Spero che la loro terminologia e le differenze possano esserti chiare ora. Diamo un’occhiata ad alcuni esempi pratici sul nostro sistema Linux per capirli meglio.
Comprendere buffer e cache con esempi
Puoi monitorare e gestire l’utilizzo del buffer e della cache in Linux utilizzando vari strumenti come “free“, “top“, E “vmstat“. Questi strumenti forniscono informazioni sull’utilizzo della memoria, inclusi buffer e cache.
Per vedere una stima migliore di quanta memoria è realmente libera e utilizzata dal buffer o dalla cache, esegui:
$ free -mh
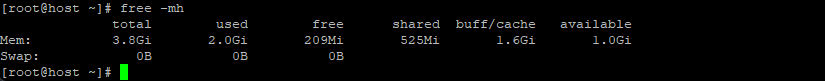
Ripartizione dei comandi:
-m: mostra l’output in megabyte-h: mostra l’output leggibile dall’uomo
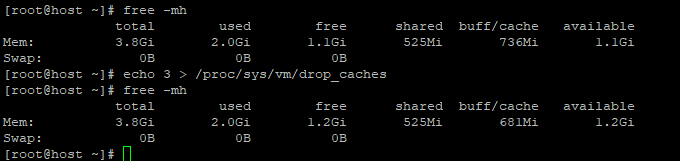
Se guardi l’immagine sopra, scoprirai che il sistema ha circa 4 GB di RAM, di cui 2,0 GB vengono utilizzati dal processo attualmente in esecuzione, 525 MB per la memoria condivisa e 1,6 GB vengono utilizzati per archiviare buffer e cache.
Linux utilizza così tanta memoria per la cache del disco per evitare che la RAM vada sprecata. Mantenere la cache significa che se qualcosa necessita nuovamente degli stessi dati, ci sono buone probabilità che siano ancora nella cache in memoria. L’accesso ai dati da lì è circa 1.000 volte più veloce rispetto al recupero dal disco rigido; se non è nella cache, è necessario leggere comunque il disco rigido, ma nello scenario della cache non si perde tempo.
Q.1: Cosa succede se desideri eseguire più applicazioni?
Quando è necessario eseguire applicazioni ad uso intensivo di risorse che richiedono più memoria, il sistema allocherà loro dinamicamente la memoria richiesta recuperandola dalle risorse già memorizzate nella cache.
Q.2: Perché top e free mostrano che la maggior parte della RAM è già consumata se non lo è?
Per capire perché la parte superiore o libera mostra direttamente la dimensione completa utilizzata per archiviare i dati del buffer o della cache, è per rendere più semplice per l’utente comprendere il consumo di memoria nel proprio sistema Per capirlo correttamente, è necessario acquisire familiarità con termini come occupato, usato, libero e disponibile in Linux, mostrati nella tabella seguente:
| Memoria utilizzata da | Lo chiameresti | Linux lo chiama |
|---|---|---|
| Esecuzione di applicazioni | Occupato | Occupato |
| Buffer e memorizzato nella cache | Usato | Usato (e disponibile) |
| Il resto della memoria | Libero | Libero |
Quindi, in parole povere, la memoria utilizzata dal buffer e dalla cache potrebbe mostrare nell’output del comando libero che vengono utilizzati, ma dietro le quinte sono anche disponibili, ma solo quando c’è domanda.
Q.3: Da dove provengono i dati mostrati nel comando top o free?
I dati effettivi visualizzati dai comandi top e free provengono dal “/proc/meminfo“, un tipo speciale di file in Linux che fornisce informazioni dettagliate sull’utilizzo della memoria e sulle statistiche del sistema.
Puoi leggere direttamente questo file usando il comando cat per ottenere informazioni sulla memoria del tuo sistema.
$ cat /proc/meminfo

I valori in “/proc/meminfo” sono riportati in kilobyte (KB) e potrebbe essere necessario interpretarli e analizzarli insieme ad altri strumenti e comandi di monitoraggio del sistema per ottenere una visione completa dell’utilizzo della memoria.
Questi dati vengono spesso utilizzati dagli amministratori di sistema e dagli sviluppatori per verificare lo stato delle risorse di memoria e identificare potenziali problemi relativi all’utilizzo della memoria per la diagnosi.
Dimostrazione del funzionamento di buffer e cache in Linux
A questo punto, hai capito che il buffer viene utilizzato per memorizzare nella cache i dati che stanno per essere scritti, mentre la cache è i dati che sono già archiviati o memorizzati nella cache in memoria e utilizzati per leggere i dati dai file.
Ma c’è una differenza: il buffer può essere utilizzato anche per la lettura e la cache può essere utilizzata anche per la scrittura. Lasciatemi spiegare con un esempio.
Prima di condurre questo esperimento, assicurati di disporre di un sistema Linux con le autorizzazioni appropriate per creare e manipolare file.
Sperimentare con Buffer
Per iniziare, apri il terminale e inizia con una cache vuota. È possibile svuotare la cache del filesystem utilizzando il seguente comando:
$ free -mh $ echo 3 > /proc/sys/vm/drop_caches $ free -mh
Produzione:
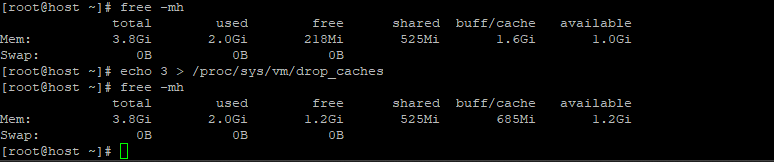
Il comando “echo 3 > /proc/sys/vm/drop_caches” viene utilizzato per cancellare i dati memorizzati nella cache della pagina del kernel Linux. Mentre “3” significa che cancella sia la cache della pagina che la cache dello slice.
Ora esegui quanto segue “vmstat 2” nella stessa finestra del terminale per monitorare e visualizzare le statistiche sulle prestazioni del sistema relative alla memoria virtuale a intervalli regolari (2 secondi in questo caso).
$ vmstat 2
Produzione:
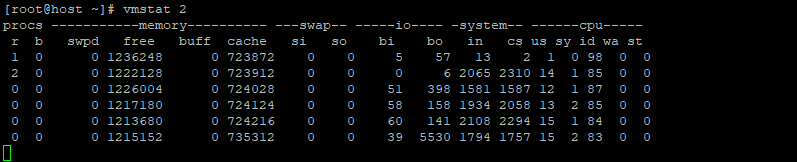
Nell’immagine sopra, devi concentrarti solo sul “buff”, che sta per buffer, e il “cache“, che sta per colonna cache e l’unità è misurata in KB. Eseguendo il comando “vmstat 2” comando e osservare i cambiamenti nel “buff“colonna.
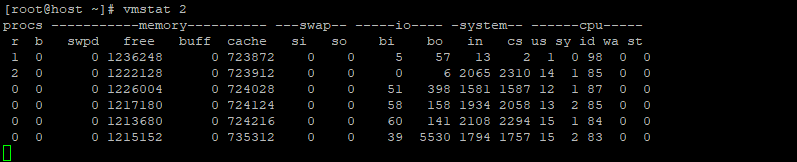
Quando esamini il “buff” E “cache“, noterai che durante l’utilizzo del comando dd per leggere il disco, le dimensioni del buffer e della cache aumentano, ma il buffer presenta una crescita significativamente più rapida.
Sperimentare con la cache
Per questo esperimento, apri nuovamente una nuova finestra di terminale o utilizza quella esistente per svuotare la cache del filesystem utilizzando il seguente comando:
$ free -mh $ echo 3 > /proc/sys/vm/drop_caches $ free -mh
Produzione:
Ora esegui quanto segue “vmstat 2“comando nella stessa finestra del terminale.
$ vmstat 2
Ora torna immediatamente alle finestre del terminale precedente, eseguendo il comando “vmstat 2” comando e osservare i cambiamenti nel “cache“colonna.
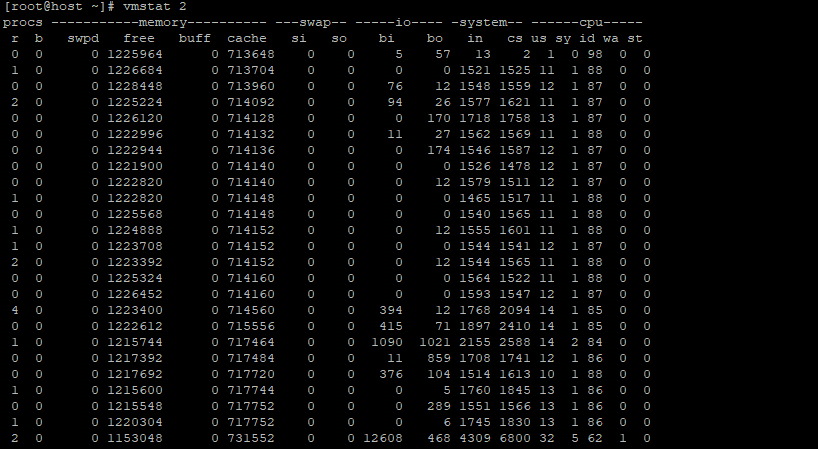
Osservando il “cache“, trovi che il comando dd continua a eseguire operazioni di lettura e scrittura nella memoria mentre il “buffer” rimasto invariato. Ciò significa che durante la lettura dal disco i dati vengono archiviati nel buffer, mentre la lettura di un file comporta l’archiviazione dei dati nella cache.
Parola finale
In parole semplici, puoi capire che un buffer è qualcosa che può memorizzare nella cache i dati che devono essere scritti o i dati che verranno letti dal disco. Mentre la cache viene utilizzata per memorizzare nella cache i file che vengono letti o scritti.