Il web crawler è emerso con la nascita dei motori di ricerca. Miravano ai motori di ricerca per raccogliere e indicizzare i collegamenti su Internet e per consentire alle persone di accedere alle informazioni in modo rapido e preciso.
Come è nato il Web Crawler?
Il web crawler è emerso con la nascita dei motori di ricerca. Miravano ai motori di ricerca per raccogliere e indicizzare i collegamenti su Internet e per consentire alle persone di accedere alle informazioni in modo rapido e preciso. In breve, sembra monitorare i collegamenti e raccogliere informazioni.
Perché sono stati dati i nomi Crawler e Spider?
Infatti, come ho detto sopra, è la ripetizione degli stessi processi (monitoraggio dei collegamenti) a determinati intervalli di tempo, la parola crawl viene confrontata con alcune azioni compiute da neonati e rettili per raggiungere l’obiettivo, il monitoraggio dei collegamenti e la crescita della struttura del network è paragonato alla tessitura del network.
Qual è la logica di funzionamento semplice del web crawler?
- Scarica pagine web
- Rimuovi collegamenti
- Elimina le parole chiave
- Passa informazioni su parole e pagine all’indicizzatore
- Continua dal link in cui ti trova e ripete gli stessi passaggi.
Come funziona un crawler?
Proprio come i social bot e i chatbot, anche i crawler sono costituiti da un codice di algoritmo e script che fornisce compiti e comandi chiari. Il crawler ripete le funzioni specificate nel codice in modo indipendente e continuo.
I crawler si muovono nel web attraverso i collegamenti ipertestuali di siti web esistenti. Inoltre valutano parole chiave e hashtag, indicizzano i contenuti e gli URL di ogni sito web, copiano pagine web e aprono tutti o solo una selezione degli URL trovati per analizzare nuovi siti web. I crawler controllano anche l’attualità di link e codici HTML.
Utilizzando speciali strumenti di analisi web, i web crawler possono valutare le informazioni come le visualizzazioni della pagina e i link e analizzare in modo mirato i dati nell’ambito del data mining.
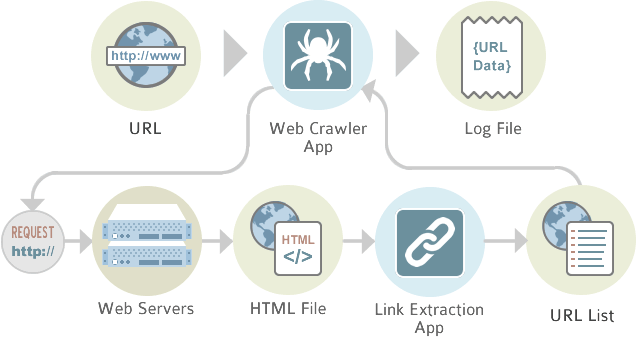
Quali sono i concetti del web crawler?
L’argomento dei concetti può essere ampliato, ma ci sono due concetti più utilizzati in generale. Crawler focalizzato e crawler distribuito.

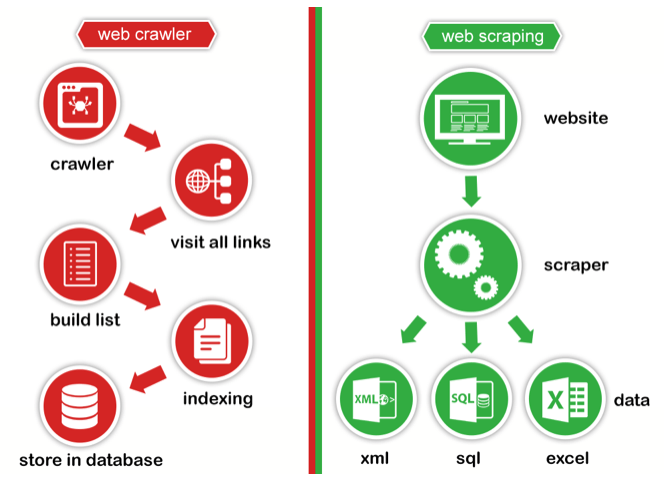
Web Crawler vs Web Scraping
In breve, i link del web crawler stanno guardando, elencando, indicizzando. Come gli spider, i bot che i motori di ricerca come Google, Yandex, Yahoo, Bing inviano ai siti.
Il Web Scraping è la raccolta e l’elaborazione di determinate informazioni a seconda della richiesta della persona.
Il web crawling / scraping è legale?
La scansione del Web è un affare legale. La parte illegale non è raccogliere dati, ma analizzarli dopo averli raccolti, dare un senso ai dati e venderli alle istituzioni. Oltre a questo, ci sono regole a cui dobbiamo prestare attenzione durante la raccolta delle informazioni.
Finché la scansione del Web non viene eseguita correttamente, puoi essere bloccato o, peggio, andare in crash dall’altra parte. Puoi eseguire una sorta di attacco DDOS.
A cosa dobbiamo prestare attenzione
Il punto a cui dobbiamo prestare attenzione qui è che usiamo le risorse del sistema opposto durante la raccolta delle informazioni. Naturalmente, molti siti adottano precauzioni di sicurezza riguardo a questi problemi, anche se lasciano alcune regole da seguire durante la scansione del sito in robots.txt. Come il limite di tempo, le informazioni sull’agente utente.
Ad esempio, volendo accedere a più di un collegamento entro un certo periodo dallo stesso indirizzo IP, filtrando in base a User-Agent …
Considerandoli durante la progettazione del sistema e del crawler, dobbiamo visitare i siti con tempi umanitari (tempo di cortesia), non come attaccare il sistema.
Tipo di crawler
Esistono diversi tipi di web crawler che differiscono per obiettivo e portata.
Crawler di motorri di ricerca
Il tipo di web crawler più datato e comune sono i bot di ricerca di Google o altri altri motori di ricerca Yahoo, Bing o DuckDuckGo. Questi bot visualizzano, raccolgono e indicizzano i contenuti web per ottimizzare la portata e il database dei engine di ricerca. I web crawler più famosi sono:
GoogleBot (Google)
Bingbot (Bing)
Slurpbot (Yahoo)
DuckDuckBot (DuckDuckGo)
Baiduspider (Baidu)
Yandex Bot (Yandex)
Sogou Spider (Sogou)
Exabot (Exalead)
Facebot (Facebook)
Alexa Crawler (Amazon)
Quali vantaggi offre un crawler?
Conveniente ed efficace: i web crawler si occupano di attività di analisi dispendiose in termini di tempo e costi e possono scansionare, analizzare e indicizzare i contenuti web più velocemente e in modo più economico e completo rispetto agli esseri umani.
Facile da usare, ampia portata: l’implementazione dei web crawler è facile e veloce e garantisce una raccolta e un’analisi dei dati completa e continua.
Miglioramento della reputazione online: i crawler ottimizzano il vostro marketing online espandendo e focalizzando lo spettro di clienti. La reputazione online di un’azienda può anche beneficiare della cattura di modelli di comunicazione sui social media grazie ai crawler.
Pubblicità mirata: il data mining e la pubblicità mirata permettono di rivolgersi a gruppi di clienti specifici. I siti web con una frequenza di scansione più elevata sono elencati più in alto nei motori di ricerca e ottengono più visualizzazioni.
Valutazione dei dati di clienti e di quelli aziendali: i crawler consentono alle aziende di valutare, analizzare e utilizzare i dati dei clienti e delle aziende disponibili online per ottimizzare la propria strategia di marketing e imprenditoriale.
Ottimizzazione SEO: valutando termini di ricerca e parole chiave, è possibile definire frasi chiave, limitare la concorrenza e aumentare le visualizzazioni delle pagine.
Altri possibili contesti d’uso sono:
- monitoraggio continuo dei sistemi per identificare punti deboli
- archiviazione di siti web datati
- confronto di siti web aggiornati con le vecchie versioni
- ricerca e rimozione di collegamenti inattivi
- valutazione del volume di ricerca delle keyword
- rilevamento di errori ortografici e altri contenuti non corretti